(Смотрите запись https://vimeo.com/226001966 или читайте текст ниже)
Расскажу о лёгкости тестирования "белым ящиком".
Многие уверены, что проверкой кода должен и может заниматься только высокий профессионал, имеющий опыт написания сложных программ и досконально знающий язык программирования. Но вскоре вы поймёте, что эту работу вполне можно дать вчерашнему школьнику со знаниями Информатики и Мат-Анализа.
Надеюсь, вам известно, что основными причинами серьёзных багов являются элементарные опечатки, недоправки копи-пастов и даже отсутствие кода, поэтому предлагаю проводить тестирование «белого ящика» при помощи утилит аудиторов кода:
* даже юниоры убедятся, что проверка сорсника – это не сложно;
* определим полезные визуализаторы и метрики кода;
* в процессе будут подсказки по выбору и использованию утилит.
Неколько примечаний:
- примеры кода написаны на языке PL/SQL Oracle;
- Все умозаключения по применению основаны на собственном опыте;
- Дабы избежать маркетинговых проблем и не поощрять вашу лень при интернет-поиске, никаких конкретных названий продуктов упомянуто не будет. А также советов, как у программиста взять код для теста, это «интимный» вопрос. Даже профи-аудитору код дают после утряски юридических вопросов. Предположим, что сорсник хотя бы на чтение уже в нашем распоряжении;
- Под юнитом/сорсником/подпрограммой/кодом будем иметь ввиду обычный текстовый файл с листингом программы.

Как работают утилиты, которыми пользуются аудиторы кода:
- Сначала Парсер разбивает текст на строки: значимые (сами команды) и вспомогательные (комментарии, пустые строки);
- Потом Лексер по значимым строкам определяет структуру кода: подпрограммы, команды, параметры и тому подобное;
-
Визуализатор генерит диаграммы;
- Анализатор высчитывает
метрики кода и по этим данным формирует предупреждения о нарушенных правилах кодирования. Списком таких «нарушений» удобно пользоваться при проведении code review, но не всегда утилиты статического анализа имеют подробные расшифровки и рекомендации по устранению ошибок. Поэтому при подборе утилит обращайте внимание на то, есть ли возможность создать свои правила проверки кода и устанавливать иные лимиты на метрики.

Приведу несколько примеров помощи тестировщику от визуализаторов кода.
Самый простой визуализатор, как ни странно, - комментарии. Их игнорируют программисты, оправдываясь правильно-названными компонентами кода, хотя, не все считают обязательным удалять закомментированные строки кода. А поскольку они не являются полезными комментами, то от них надо избавляться, благо есть система контроля версий. При наличии полезных комментов не так опасно потерять СКВ или баг-трекинговую систему (историю задачи можно восстановить по комментариям).
Если к правильным комментариям добавить специальные теги, то получится документор кода или псевдокод. Когда же чистая выборка документора совпадает с текстом аналитика хотя бы по логичности распределения команд в коде, тестировщик может автоматически закрывать чек-лист про покрытие кодом спецификации задачи. А поскольку некоторые утилиты по комментам псевдокода строят блок-схемы, то сравнение с UML диаграммой аналитика даст объём тех-задания, не покрытого кодом, моментально.
Ясное дело, наличие комментов зависит только от программиста, который не очень-то любит писать обычные тексты, но его можно легко уговорить на ведение комментов, если составлять их как план подпрограммы из текста аналитика, а потом к ним дописывать код. Они помогут следующему кодеру разобраться в программе.
При тестрировании через комментарии, юниору не нужны знания синтаксиса языка, и даже более того – по ним можно изучать программирование.
К слову сказать, крупные компании ведут комментарии кода в обязательном порядке и по своим правилам/шаблонам. Когда же StartUp-у захочется сертифицироваться, то код уже придётся документировать.

Вторая группа
визуализаторов, полезных тестировщику, показывает ход программы. Это: блок-схемы, Flowchart, UML диаграммы по готовому листингу.
Мощнейшая утилита из портфеля аудитора! По нарисованному коду, даже без знаний синтаксиса языка, сразу видна масса багов или тем на рефакторинг:
- количество блоков всегда можно подсчитать, и в некоторых утилитах выставить лимит. Если диаграмма большая, то сорсник длинный. А «лапша» всегда была поводом для оптимизации кода;
- находите дубликаты блоков через поиск текста в блоках и подсветку путей, чтобы проверить их на проблемы после копи-паста (недоредактированный код), либо оформить внутреннюю задачу для рефакторинга по выносу повторений в отдельную функцию (повторяющиеся блоки - причина будущих опечаток и недоправок, а унифицированные функции ускоряют правки и переделки);
- сворачиваемость блоков и подсветка определённых путей ("Да", "Нет", "Исключение") более чётко покажут недостаточно обработанные условия и отсутствие кода. А когда фича не дописана, то тестировщику нет смысла тратить время на проверку пустот (сразу возвращайте на доработку);
- мёртвый код ищется два месяца «чёрным ящиком», а при использовании flowchart определяется за пару минут путём сравнения с диаграммой или текстом от аналитика;
- кликабельность из блоков в строки кода помогает обнаружить замедления, которые бывают от наличия комментариев или обращений к базе внутри цикла (обычно в схеме flowchart не показывается текст комментариев, поэтому их наличие придётся выявлять в самом коде, а визуализацию циклов легче определить по диаграмме);
- глазастые заметят в примере переменные без присвоенного значения или неочищенные в конце (проблем от некорректного обращения с переменными множество - от переполнения буфера и до некорректного расчёта и передачи в другие модули).
Утилиту для построения блок-схем чаще других можно найти в среде разработки программиста. Также много аналогов в свободном доступе.

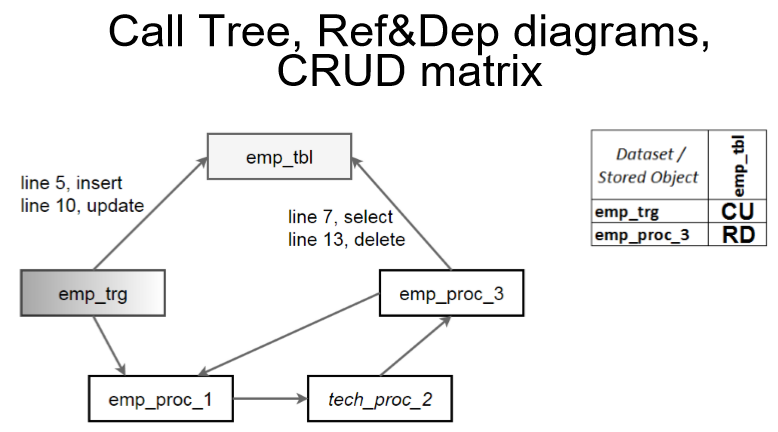
Третья группа визуализаторов – демонстрирует вызовы одних подпрограмм другими и показывает связи объектов данных с кодом. Их называют обычно Call Tree, References&Dependencies диаграммы (направления стрелок показывают вызовы объектов) и CRUD матрица (Create/Read/Update/Delete операции над данными из подпрограмм).
Сорсники и таблицы всего проекта попадают без повторений в диаграмму. Поэтому простым поиском по имени выявляйте лишние и недостающие обращения к объектам. Например, в диаграмме о кадрах может быть лишней процедура "tech_proc_2", а в матрице бухгалтерии или финансового отдела часто можно обнаружить нехватку процедур или таблиц с ордерами прихода/расхода (если существует корпаративные стандарты наименований объектов).
Для генерации диаграмм и матриц берите чистый исходный код, не прошедший обфускацию или компиляцию, потому что замена имён не даст нужного результата.
Пользуйтесь детализацией связей, подсветкой вызовов и сменой уровней связей при поиске зацикленных процедур (в примере процедура "tech_proc_2" должна быть проверена на все вызовы процедурами "emp_proc_1" и "emp_proc_3", так как при определённых условиях вполне может случится зацикливание), а также шагов, приводящих к мутации данных (в примере показан триггер "emp_trg" и процедура "emp_proc_3", влияющие на данные в таблице "emp_tbl", а поскольку процедура через несколько шагов может быть выполнена из триггера, то вполне вероятно совместное обращение к одним и тем же данным).
Если формат выходной диаграммы SVG, XML или VDX, то более вероятно воспользоваться всеми полезностями (поиск по диаграмме, подсветка путей, кликабельность из диаграммы в код, сворачиваемость блоков диаграмм).

А теперь немного о
метриках кода, то есть о качестве в цифрах. Если визуализаторы более полезны на начальном этапе разработки, то на метрики кода влияют каждые изменения подпрограммы. К сожалению, идеального кода не существует и добиться невозможно, как и КПД-100%. Чем же мы, тестировщики, в состоянии помочь кодеру?
Самая простая метрика -
количество строк в сорснике до компиляции. С этим файлом работает программист в среде разработки – правит, отлаживает, компилирует. А большой объём файла совсем не на руку ни компилятору, ни системе контроля версий, ни тем более среде разработки.
Хороший редактор раскрашивает синтаксис, показывает начало-конец цикла и иными способами помогает кодеру, а все эти примочки требуют ресурсов. В один прекрасный день вчерашний код не откроется в среде разработки – и конец всем фиксам.
В СКВ дешевле хранить некоторые маленькие файлы, нежели один и тот же большой дописывать, потому что место на сервере слишком быстро закончится.
Слияние изменений (merge) выполнять в СКВ на мелких отдельных файлах проще, и конфликты случаются реже - как в коде, так и между сотрудниками.
Вторая простая для подсчёта величина –
количество параметров (и особенно глобальных), которое рекомендуют не более 7 (5 входящих, 2 на выход). Цифра пришла из чистой психологии - единовременно человек запоминает не более 7 объектов. Для работы с бОльшим количеством параметров придётся взводить хинты-подсказки, требующие ресурсов и времени.

С 70-х годов XX века благодаря T.J.McCabe, Maurice Halstead, и чуть позже Don M Coleman и Paul Oman с Jack Hagemeister стало возможным
измерить качество кода и спрогнозировать его развитие. Величины, выведенные этими людьми, стали носить их имена.
Thomas J.McCabe вывел формулу
цикломатической сложности юнита как
разность рёбер и узлов с добавлением удвоенного количества компонент связности.
При грубой оценке граф цикломатической сложности совпадает с диаграммой flowchart, где стрелки выполняют роль рёбер (на рисунке - зелёные), овалы и многоугольники считаются узлами (на рисунке - красные звёздочки), а целый законченный блок – компонент связности (на рисунке - серым цветом ограничены два графа для примеров кода).
Не для всех случаев граф цикломатической сложности идентичен flowchart, потому что если используется сложное условие (через OR/AND), то каждое из них может считаться узлом (в примере граф для процедуры "threeinone" станет идентичен графу для процедуры "oneinthree").
Максимальное значение величины McCabe утверждено Американским Национальным Институтом Стандартов и Технологий (NAST), равно
10, но последнее время расширяют до 15.
Нам тестировщикам это значение говорит о необходимом
количестве юнит-тестов.

Все величины Мариуса Халстеда рассчитываются по
операторам и
операндам, и поэтому утилита должна быть версионно-зависимой для языка программирования, а лучше встроенной в среду разработки.
Что есть операторы и операнды помним, да? В выражении «a+b»: "+" – оператор, "a" и "b" – операнды.
Не удивляйтесь, если подсчитанные строки в листинге не совпадают с длиной программы по Халстеду, потому что
длина программы – это
сумма всех операторов и всех операндов.
Словарь юнита он определил как
сумму уникальных операторов и операндов.
А
помножив длину программы на логарифм словаря, Халстед получил
объём подпрограммы (или ещё эту величину называют "
сложностью Халстеда"). Она
максимально не должна превышать 1000 (лимит не утверждён никаким стандартом).
Если же исследовать функцию сложности, приняв уникальными все операнды и операторы, то в самом сложном юните должно быть примерно – 45 операторов и 90 операндов, как это видно на графике. Фактически - это невообразимая программка.

Maintainability Index перевожу для себя не как ремонтопригодность, а как «важность и устойчивость», потому что он
прогнозирует развитие подпрограммы (сколько ещё можно править или расширять юнит).
Индекс значимости подпрограммы, выведенный Доном Колеманом и Паулем Оманом, дополненный Джеком Хейгмейстером, зависит от всех составляющих листинг:
операторов и
операндов,
блоков и их
связей, значимых и вспомогательных
строк кода.
Предел индекса никакими институтами пока не утверждён, но для
стабильно-устойчивых подпрограмм рекомендуется писать код так, чтобы индекс был
более 85. Когда индекс падает
ниже 65, то ваш юнит совсем
плох.
Если поисследовать функцию, рассчитывающую индекс, то при максимальных величинах Халстеда, МакКейба и комментов в одном юните - не стоит делать более 1500 строк. Это видно на среднем графике.
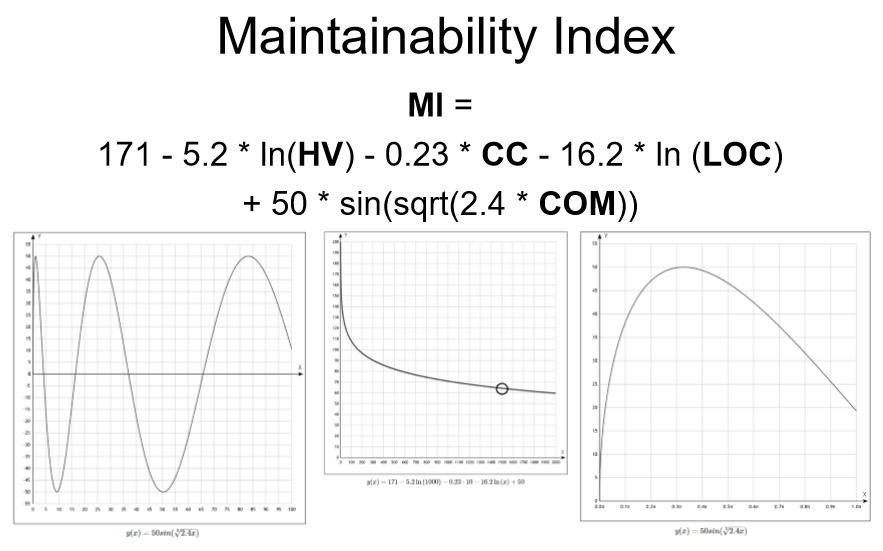
Формула имеет
две модели: с учётом комментариев (обе строки формулы:" MI = 171 - 5.2*ln(HV) - 0.23*CC - 16.2*ln(LOC) + 50*sin(sqrt(2.4*COM)) ") и без учёта комментариев (только первая строка: " MI = 171 - 5.2*ln(HV) - 0.23*CC - 16.2*ln(LOC) "). Поскольку величина комментариев зависит от функции синуса, то при отношении объёма комментов к строкам кода в
процентах, синусоида сложно извивается на отрезке от 0 до 100 (
левый график показывает несколько вариантов подбора - максимумы). Если же брать
долевое исчисление комментов - от 0 до 1 (
правый график), то
3/10 комментированных строк дадут максимум
полезности. Юнит должен быть легко-читаемым. И даже цифры подтверждают, что нет смысла экономить за счёт комментариев: "+50 всегда лучше трёх минусов для стремящихся к 85 и выше".

В таблице-шпаргалке перечислены формулы для исчисления качества кода. Особым шрифтом выделены две формулы для прогноза количества багов (вывел Халстед).

При использовании аудита кода, как части среды разработки, никаких дополнительных вложений от вас не потребуется: ни в обучение, ни в покупку, ни в дальнейшую поддержку утилит, как это приходится делать с юнит-тестами.
Если результаты юнит-тестов дают понимание о том, «каков код здесь и сейчас», то аудит говорит о перспективах развития подпрограммы.
Code Audit - для комплексного тестирования всего проекта, Unit testing – для точечного.
Одно другим подменить невозможно, но совместное использование только улучшит качество конечного продукта.
Мечтающие взлететь в bug-bounty, воспользуйтесь тем, что завалялось у вашего программиста, а именно утилитами аудиторов кода, вшитые в среду разработки.
Делайте аудит кода, находите сразу причины сложных багов, давайте подсказки программистам, где именно и что рефакторить для улучшения качества кода. Или научите их делать аудит кода самостоятельно, регулярно, автоматически через шедулеры, и в тестировщиках отпадёт необходимость.